背景
vertx是一个我去年看完netty就一直想看看的工具,但因为拖延加懒,最近才看了看文档写了写demo, 算是对它有了一点点了解,之所以想写一点,其实是想自己给自己总结下vertx的一些核心的概念。
vertx core
vertx core 提供了一些 vertx的基本操作,如经常用到的
- 编写TCP客户端和服务器
- 编写HTTP客户端和服务器
- EventBus
- file操作
- HA
- 集群
先上一段代码看下vertx创建一个httpServer:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28 //创建一个vertx实例
VertxOptions vo = new VertxOptions();
vo.setEventLoopPoolSize( 1);
Vertx vertx = Vertx.vertx(vo);
vertx.deployVerticle(MyFirstVerticle.class.getName());
DeploymentOptions().setInstances(2)
//MyFirstVerticle.java
public class MyFirstVerticle extends AbstractVerticle {
public void start() {
vertx.createHttpServer().requestHandler(req -> {
System.out.println(Thread.currentThread());
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
req.response()
.putHeader("content-type", "text/plain")
.end("Hello World!");
this.deploymentID();
Context c=vertx.getOrCreateContext();
}).listen(8080);
}
}
vertx实例是最核心的一个对象 是宁做几乎一切事情的基础,包括创建客户端和服务器、获取事件总线的引用、设置定时器等等。
是不是很想说一句,嗨,就这,不就nodejs吗
EventLoop
EventLoop算是vertx的基本模型了,简单的讲就是所有的操作都是以 触发 的方式来进行,将IO的操作完全交给vertx,开发者真正要关心的是IO各个阶段的 事件 ,讲的朴素一点就像是js的回调函数一样。
个人觉得vertx的EventLoop 基本等同于Netty的模型,如果真要探索起来,怕是要从Linux的多路复用,select函数,java的NIO,和netty一路将过来了,所以尝试用画图的方式来更形象的描绘: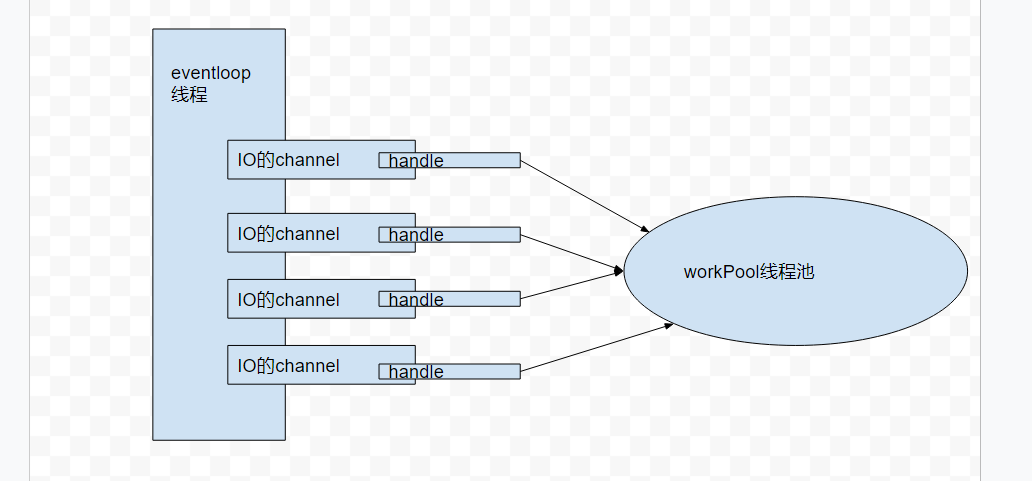
其实EventLoop 就是一条线程,上面挂的每一个channel就是一个IO连接,底层利用的就是IO多路复用加select 或poll,epoll,来保证每一个线程可以保证控制很多个IO连接,而每一个连接都会挂一个handler,来处理这个连接的 每一个事件 例如:init,connected,read.writer,close。
这个模型的左半部分同样适用于netty。右半部分有一个workPool是一个线程池,是vertx新增的东西,是用来专门处理耗时操作的,如 file,阻塞的DB操作,为什么要加这个概念哪,因为不要阻塞EventLoop是NIO的基本守则。
阻塞操作操作代码如下:1
2
3
4
5
6
7
8
9
10executor.executeBlocking(future -> {
System.out.println("Action Thread"+Thread.currentThread());
// 调用一些需要耗费显著执行时间返回结果的阻塞式API
String result = blockingMethod("hello");
future.complete(result);
}, res -> {
System.out.println("Handler Thread"+Thread.currentThread());
System.out.println("The result is: " + res.result());
executor.close();
});
verticle
verticle 其实一直是让我困惑的一个概念,因为vertx的主要运行,基本都是围绕vertx实例来进行的,后面我为verticle找到了一个合理的角色,叫他为vertx实例的一个发布单元,什么是一个 发布单元哪,举个例子,一个HttpServer的发布是一个发布单元。
verticle具有以下几个特点:
- 每个verticle占用一个EventLoop线程,且只对应一个EventLoop
- 每个verticle中创建的HttpServer,EventBus等等,都会在这个verticle回收时同步回收
- 在多个verticle中创建同样端口的httpServer,不会有错误,会变成两个EventLoop线程处理同一个HttpServer的连接,所以多核机器,肯定是需要设置多个verticle的实例来加强性能的。
可以这么想,vertx实例就是一台服务器,而verticle就是上面跑的进程。
EventBus
EventBus 是沟通verticle的桥梁,且可沟通集群中不同vertx实例的verticle,操作很简单。这个似乎概念很简单,就是队列呗,上段代码看看:1
2
3
4
5
6
7
8
9
10
11
12//创建一个EventBus
EventBus eb = vertx.eventBus();
req.bodyHandler(totalBuffer -> {
eb.send("news.uk.sport", totalBuffer.toString("UTF-8"));
});
//消费
EventBus eb = vertx.eventBus();
eb.consumer("news.uk.sport", message -> {
System.out.println("前台传入的内容:" + message.body()+""+this);
});
模型如图: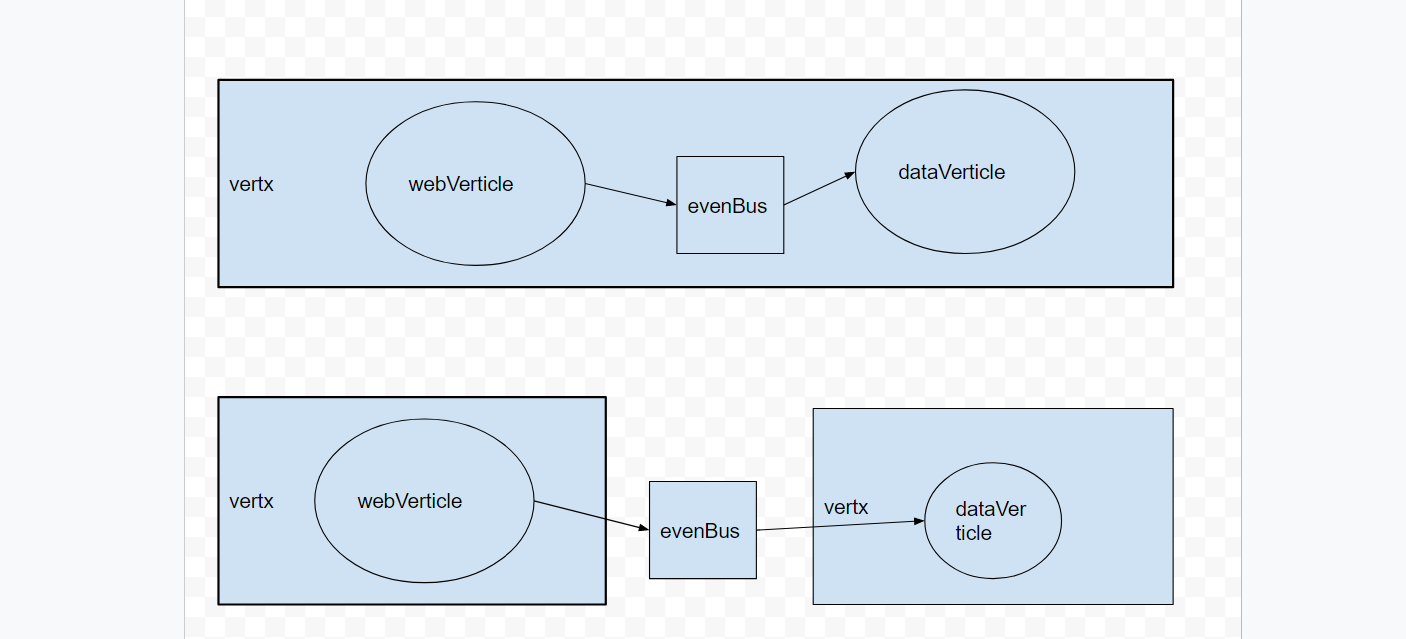
vertx web
vertx core已经提供了基本的HttpServer的操作,但实际上功能远远不够正常的开发,所以vertx web作为一个拓展包,是web开发必须的。他提供了一个基本概念router,来进行各种匹配,使得请求能进入正确的handler,其实就是有点springMvc的各种路径匹配。使用起来代码:
1 | HttpServer server = vertx.createHttpServer(); |
web包括的功能很多,有各种匹配,content-type匹配,路径规则匹配,CROS,错误处理,文件传输 等等
vertx fileSystem
vretx中的文件操作主要采用了javaNio包中的文件操作,通过看源码我们可以发现文件操作也是运行在workPool中的,看下代码:1
2
3
4
5
6
7
8
9fs.copy("C:\\Users\\Administrator\\Desktop\\Untitled-4.txt", "C:\\Users\\Administrator\\Desktop\\ss.txt", res -> {
System.out.println("file copy handle" + System.currentTimeMillis());
System.out.println("file copy handle" + Thread.currentThread());
if (res.succeeded()) {
System.out.println("success");
} else {
System.out.println("error");
}
})
源码:1
2
3
4
5
6
7
8//FileSystemImpl.java
/**
* Run the blocking action using a thread from the worker pool.
*/
public void run() {
context.executeBlockingInternal(this, handler);
}
vertx DB
vertx其实提供了 两种数据库操作。一种是正常的jdbc操作,一种是异步非阻塞的数据库操作,但是只限于PG和mysql。
jdbc操作
看一段代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18JDBCClient client = JDBCClient.createShared(vertx, new JsonObject()
.put("url", "jdbc:postgresql://localhost:5432/postgres")
.put("driver_class", "org.postgresql.Driver")
.put("max_pool_size", 30).put("user","postgres").put("password","postgres"));
client.getConnection(res -> {
if (res.succeeded()) {
SQLConnection connection = res.result();
connection.query("SELECT * FROM userb", res2 -> {
if (res2.succeeded()) {
ResultSet rs = res2.result();
System.out.println(rs.toJson());
}
});
} else {
System.out.println("连接失败"); }
});
点进去发现:其实做的还是阻塞操作,1
2
3
4
5
6//AbstractJDBCAction.java
public void execute(Connection conn, TaskQueue statementsQueue, Handler<AsyncResult<T>> resultHandler) {
this.ctx.executeBlocking((future) -> {
this.handle(conn, future);
}, statementsQueue, resultHandler);
}
异步数据库操作
这我一直很好奇的,因为jdbc在天然上就是阻塞的,所以要想做到数据库的异步,就得放弃厂商提供的driver,自己做一套编解码,看下代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24PgConnectOptions connectOptions = new PgConnectOptions()
.setPort(5432)
.setHost("localhost")
.setDatabase("postgres")
.setUser("postgres")
.setPassword("postgres");
// Pool options
PoolOptions poolOptions = new PoolOptions()
.setMaxSize(5);
// Create the client pool
PgPool client = PgPool.pool(vertx, connectOptions, poolOptions);
client.query("SELECT * FROM userb ", ar -> {
if (ar.succeeded()) {
RowSet<Row> result = ar.result();
result.forEach((r) -> response.write((String)r.getValue("name")));
response.end();
} else {
System.out.println("Failure: " + ar.cause().getMessage();
}
});
这样就能做到数据库的异步操作,且可以包含事务的控制。简直丝滑
关于数据库异步的思考
数据库异步看起来十分黑科技,但是我们应该明白的是,异步非阻塞的NIO最大的优点就在于利用很少的线程来控制更多的IO连接,这使得在超多连接,IO密集的操作中有更好的表现,但是数据库连接本来一个java系统就不会占用几个,记得以前看过一个文章讲连接数设置最好=CPUcore2磁盘数,那么数据库的NIO在一般的业务系统中,似乎并不必要。
插一个知乎上大佬的回答:
vertx模型图
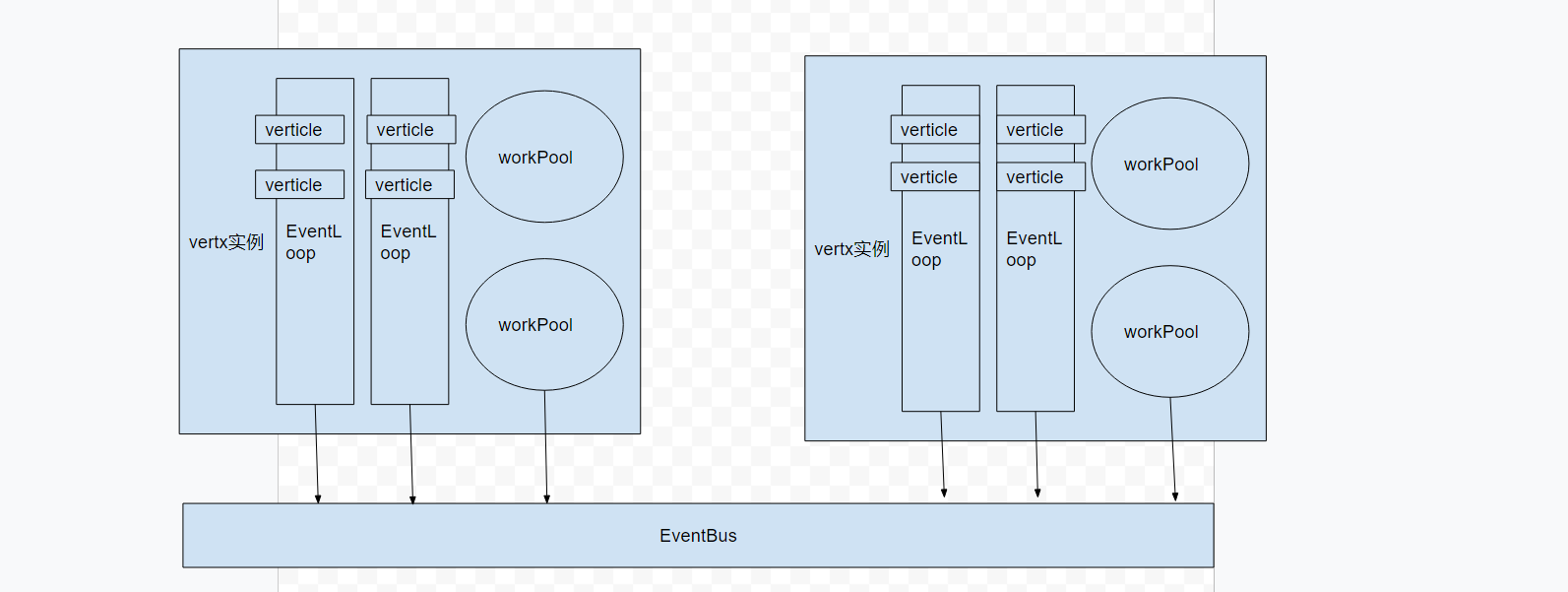
简单明了
vertx的缺点
说到缺点,明显就是回调地狱了,主要还是看过 python的协程,所以难免拿来做个比较,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25摘抄自廖雪峰的python教程
import asyncio
from aiohttp import web
async def index(request):
await asyncio.sleep(0.5)
return web.Response(body=b'<h1>Index</h1>')
async def hello(request):
await asyncio.sleep(0.5)
text = '<h1>hello, %s!</h1>' % request.match_info['name']
return web.Response(body=text.encode('utf-8'))
async def init(loop):
app = web.Application(loop=loop)
app.router.add_route('GET', '/', index)
app.router.add_route('GET', '/hello/{name}', hello)
srv = await loop.create_server(app.make_handler(), '127.0.0.1', 8000)
print('Server started at http://127.0.0.1:8000...')
return srv
loop = asyncio.get_event_loop()
loop.run_until_complete(init(loop))
loop.run_forever()
可以看到协程 可以将本该做回调的response handler变成了更符合编程习惯的方式,还是比较舒服的。
讲点废话
本来还想把demo放到github上来给像我一样懒的人直接clone下来跑的,但是确实都是官网的例子,放上去太羞耻了。
这文章写的很纠结,写详细了东西太多,写总结性的东西吧,太抽象,没看过的觉得一脸懵,懂得觉得写的没啥意义。
就这吧,如果有大佬想和我讨论或是哪里写的不对,请积极发炎。